说明:本人已经成功在公司部署DeepSeek-R1使用,并且已经投入给部分员工使用,我使用的是一台虚拟机centos7.9版本系统,这里我将部署的所有过程都截图记录下来,提供给有需要的人士使用,如觉得好用,点赞收藏转发。

1、配置主机名
系统需要自己先安装好,安装好系统之后,前提是这台机也能访问互联网,进入系统,修改主机名,这看大家,需不需要修改都可以。
[root@localhost ~]# hostnamectl set-hostname deepsee
[root@localhost ~]# bash

2、关闭防火墙
[root@deepseek ~]# systemctl stop firewalld || systemctl disable firewalld
关闭selinux
[root@deepseek ~]# setenforce 0
把配置SELINUX=enforcing改为SELINUX=disabled
[root@deepseek ~]# sed -i "s/SELINUX=enforcing/SELINUX=disabled/" /etc/selinux/config

3、下载阿里源(可选)
[root@deepseek ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
4、进入官网Ollama
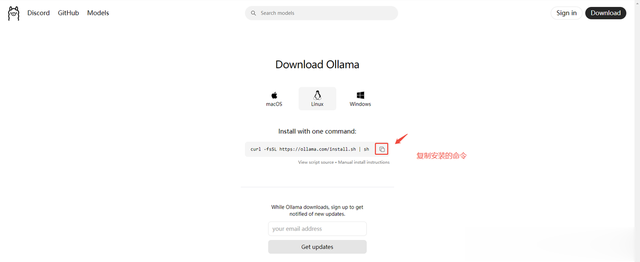
4.1 官网网站:https://ollama.com,点击:Download。

4.2 进入下载的界面,也可以window部署,但是我使用Linux部署,然后点击到:Linux,再点击复制命令:curl -fsSL https://ollama.com/install.sh | sh
5、下载并且安装
这个下载过程可能有点慢,我大概花40分钟左右,成功安装完成。如果网络快的话,就很快。
[root@localhost ~]# curl -fsSL https://ollama.com/install.sh | sh

6、服务验证以及查看命令是否可以使用
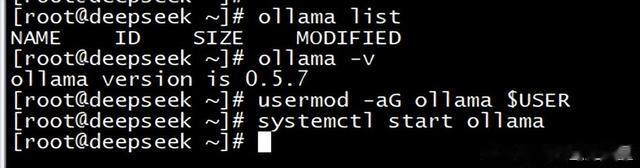
[root@deepseek ~]# ollama list #查看模型,因为刚刚安装好的还没有,需要下载模型才能看到。
NAME ID SIZE MODIFIED
[root@deepseek ~]# ollama -v #查看ollama安装的版本
ollama version is 0.5.7
[root@deepseek ~]# usermod -aG ollama $USER
[root@deepseek ~]# systemctl start ollama #启动ollama
[root@deepseek ~]# systemctl status ollama #查看ollama状态
7、下载deepseek r1 的模型
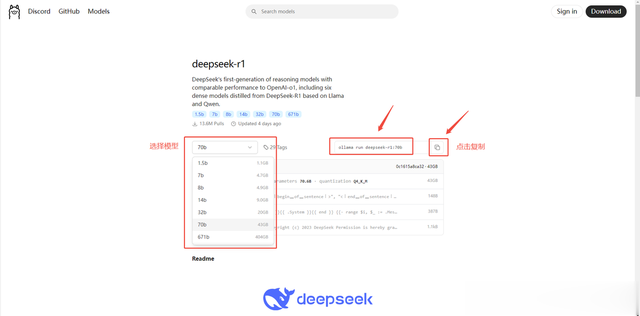
Deepseek 模型部署2.1 模型下载与加载,以 deepseek r1 模型为例:
访问官网:https://ollama.com/library/deepseek-r1,默认为 7b 模型,点击选择的时候可以看到每个模型的下载大小,根据自己的需求下载,如需其他模型,可以在当前页搜索所需模型,选选择模型后,再点击后面的复制按钮即可。比如我复制的命令:ollama run deepseek-r1:1.5b
回到Linux的界面进行执行命令下载,下载有可能会超时,如果超时了,继续执行该命令,等待下载完成即可。下载好就可以在这个界面操作>>>,这里输入文字即可聊天了,但是还需要安装页面,继续往下走。
[root@deepseek ~]# ollama run deepseek-r1:1.5b

各个模型的大小:
ollama run deepseek-r1:1.5b---------------#大小1.1G
ollama run deepseek-r1:7b-----------------#大小4.7G
ollama run deepseek-r1:8b-----------------#大小4.9G
ollama run deepseek-r1:14b---------------#大小9.0G
ollama run deepseek-r1:32b---------------#大小20.0G
ollama run deepseek-r1:70b---------------#大小43G
ollama run deepseek-r1:671b-------------#大小403G
第二次下载模型(安装时先可忽略)
上是我第一次安装时候下载的模型,我是全部安装好了,再下载大一点的模型,但是下载了好久,然后才慢慢找到规律:基本每次只能跑1%,然后手动结束,再运行,如果要跑到100%,可能需要操作100次。如果长时间没有结束就超时。
下载模型遇到的问题:ollama pull时进度回退,不知是否最近太多人下载导致服务器问题,下载大点的模型经常进度条往回退,解决方法就是每隔一会关闭进程重下载,断点续传可以
继续下载。
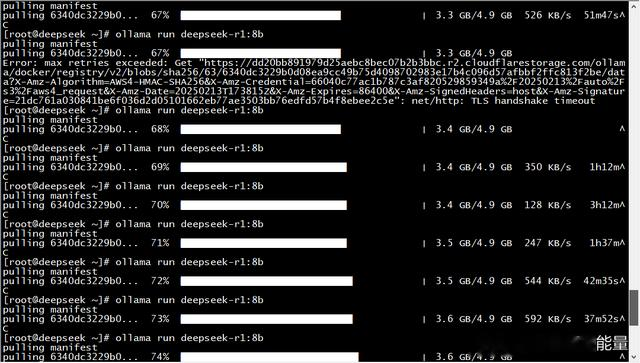
摸索着,下载了两天,终于下载完成了。

安装docker
1、时间同步
[root@deepseek ~]# yum install ntp -y #如果没有ntp命令,需要安装
[root@deepseek ~]# timedatectl set-timezone Asia/Shanghai #如果时区不对,就需要变更一下
[root@deepseek ~]# ntpdate ntp1.aliyun.com
2、安装阿里云:
安装先先做一下备份:
[root@deepseek ~]# cd /etc/yum.repos.d
[root@deepseek yum.repos.d]# mkdir back
[root@deepseek yum.repos.d]# cp -ra CentOS-Base.repo back
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
3、安装依赖包:[root@deepseek ~]# yum -y install gcc gcc-c++ yum-utils[root@deepseek ~]# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo [root@deepseek ~]# yum makecache fast

4、安装docker容器。[root@deepseek ~]# yum install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -y安装完成之后,查看版本:[root@deepseek ~]# docker version

[root@deepseek ~]# docker info #查看加速是否成功[root@deepseek ~]# systemctl enable --now docker #启动docker[root@deepseek ~]# systemctl status docker #查看状态

添加配置daemon.json,如果没有这个文件就直接创建即可:
[root@deepseek ~]# vim /etc/docker/daemon.json{"registry-mirrors": ["https://docker.registry.cyou","https://docker-cf.registry.cyou","https://dockercf.jsdelivr.fyi","https://docker.jsdelivr.fyi","https://dockertest.jsdelivr.fyi","https://mirror.aliyuncs.com","https://dockerproxy.com","https://mirror.baidubce.com","https://docker.m.daocloud.io","https://docker.nju.edu.cn","https://docker.mirrors.sjtug.sjtu.edu.cn","https://docker.mirrors.ustc.edu.cn","https://mirror.iscas.ac.cn","https://docker.rainbond.cc"]}
加载配置和重启docker
[root@deepseek ~]# systemctl daemon-reload
[root@deepseek ~]# systemctl restart docker
5、拉取openui镜像
国内源,就行这个行了。[root@deepseek ~]# docker pull ghcr.nju.edu.cn/open-webui/open-webui:main
#国外源(可不用执行)[root@deepseek ~]# docker pull ghcr.io/open-webui/open-webui:main
6、启动openui
docker run -d --net=host \-e PORT=3000 \-e OLLAMA_BASE_URL=http://127.0.0.1:11434 \-e ENABLE_SIGNUP=true \-e ENABLE_OPENAI_API=False \-v open-webui:/app/backend/data \--name open-webui --restart always \ghcr.io/open-webui/open-webui:main

7、访问页面
7.1 启动好了,就可以访问界面(可能比较慢些,等一会再访问页面),在浏览器中输入链接:http://172.16.3.4:3000,点击下面的开始使用。

7.2 第一次打开界面出现创建管理员的账号,注意:这个是创建管理员账号。输入相关信息后,点击:创建管理员账号。
7.3 创建好账号,进入的界面,点击:确认,开始使用。

7.4 左上角选择你的模型,开始问问题。
8、修改配置
接下来还需要修改一下配置,右上角点击头像,再点击:管理员面板。
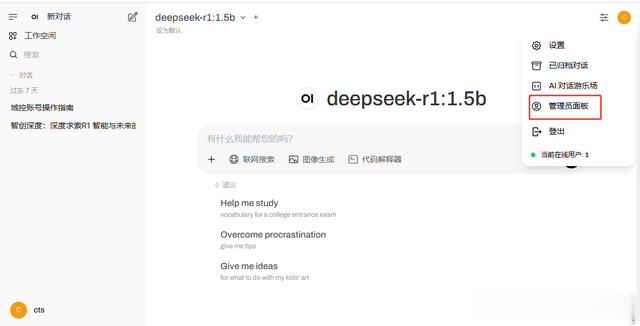
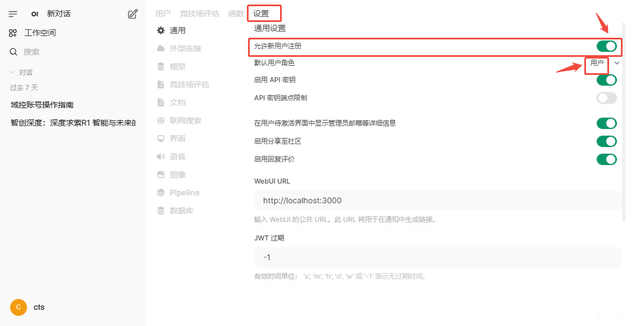
在”管理员控制面版“界面,点击”设置---通用“ 的界面,把”允许新用户注册“开关打开,,再点击”默认用户角色“选择”用户“,默认是不开启的。
在”管理员控制面版“界面,点击”设置---模型“ 的界面,
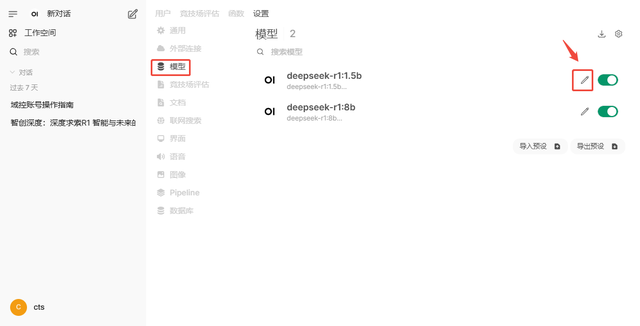
在”可见性“选择”public“,公用的,,下面点击”保持并更新“,这样其他用户才能看到这个模型,注意:默认是不开启的,用户注册了看不到。

然后其他的配置自己可以研究研究,工具自己的需求,还有很多配置可设置的。
第二次我下载的模型:

如果重启了机器,并且服务没有启动,需要手动重启一的open-webui,正常来说会启动。
停止open-webui如果需要停止open-webui,可以使用以下命令:docker stop open-webui
启动open-webui如果需要启动open-webui,可以使用以下命令:启动openui
docker run -d --net=host \-e PORT=3000 \-e OLLAMA_BASE_URL=http://127.0.0.1:11434 \-e ENABLE_SIGNUP=true \-e ENABLE_OPENAI_API=False \-v open-webui:/app/backend/data \--name open-webui --restart always \ghcr.io/open-webui/open-webui:main
注意防火墙是否重启机器后开启了
并且做了压测。
第一次:20核32G,回复问题非常慢,基本都跑不动,CPU跑到100%
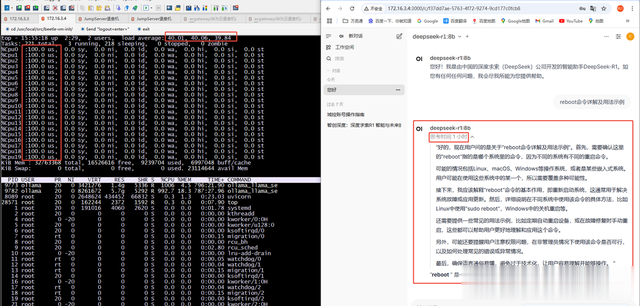
第二次:后来我加大CUP的核数,但是还是很慢,32核20G,CPU跑到95%左右了,总比第一次快好多了。

