
现代 GPU 通常在占用率和每个线程可用的寄存器数之间做出艰难的权衡。
现代的GPU常常需要在占用率(活动线程数量)与每个线程可用的寄存器数量之间艰难地做出权衡。因为更高的占用率能提供更多的线程级并行性来隐藏延迟,而更多的同步多线程(SMT)线程有助于在CPU上隐藏延迟一样。但是,CPU无论运行什么代码都可以使用其所有的 SMT 线程,而GPU不行。GPU 的指令集架构(ISA)提供了大量非常宽的向量寄存器。为所有线程槽存储所有寄存器是不切实际的,因为寄存器文件必须在容量、速度和芯片面积使用之间取得平衡。

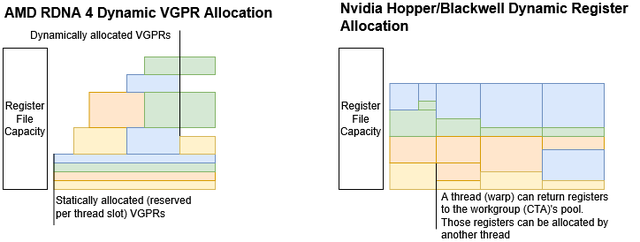
例如,RDNA 4 的指令集架构允许指令寻址多达 256 个向量通用寄存器(VGPR)。在 wave32 模式下,每个寄存器宽 1024 位,并且每个 RDNA 4 单指令多数据(SIMD)单元有 16 个线程槽。该 SIMD 单元需要一个 512 KB 的寄存器文件来为所有 16 个线程保存 256 个寄存器。实际上,不同的 GPU 工作负载对寄存器的需求各不相同。和许多其他 GPU 一样,RDNA 4 使用较小的寄存器文件,并根据线程的需求进行分配。需要大量寄存器的代码可以这样做,但代价是线程级并行性降低,而使用较少寄存器的代码可以运行更多的活动线程,并且对延迟不那么敏感。RDNA 4 桌面 GPU 每个 SIMD 单元有一个 192 KB 的寄存器文件,因此,如果一个 GPU 内核使用 96 个或更少的向量寄存器,它就可以使用所有的线程槽,实现最大占用率。

更大的寄存器文件显然可以改善占用率和寄存器使用之间的权衡情况。RDNA 将 SIMD 寄存器文件的容量从图形核心网络(GCN)架构的 64 KB 增加到了 128 KB。RDNA 3 为高端 GPU 引入了 192 KB 寄存器文件的配置,在这种情况下,芯片面积可能不是那么需要考虑的问题。但这种策略对于光线追踪来说效率不高。

AMD 指出,光线遍历和命中或未命中处理对 VGPR 的需求不同。AMD 采用了一种内联光线追踪模型,在这种模型中,所有的光线追踪阶段都在同一个线程内运行。光线追踪着色器的 VGPR 分配必须设置为任何阶段所需的最大值,因为一个线程的寄存器分配在其整个生命周期内是静态的。即使需要大量寄存器的代码只占执行时间的一小部分,在工作负载持续期间,这种高 VGPR 分配也会限制活动线程的数量。光线追踪对延迟特别敏感,AMD 希望尽可能多地并行运行线程(光线)以帮助抵消延迟。
动态寄存器分配因此,RDNA 4 引入了一种新的动态 VGPR 分配模式。在这种模式下,一个线程从最小的 VGPR 分配开始,并在其生命周期内对其进行更改。驱动程序不是指定一个着色器将使用多少个 VGPR,而是告诉 GPU 以动态 VGPR 模式启动它。一个芯片范围的 SQ_DYN_VGPR 寄存器直接设置每个 SIMD 的活动线程数量,即占用率,而不是从着色器的 VGPR 使用情况推断出来。SQ_DYN_VGPR 还控制其他动态 VGPR 模式参数,如 VGPR 分配块大小和死锁避免模式。

正如 Linux 内核代码中所定义。我们在 Linux 或 LLVM 中都没有找到相关的引用或用法,故对每个字段的作用推理假说。
每个启用的线程槽都会得到一个单独的保留 VGPR 块,新启动的线程一开始只有这个 VGPR 块处于活动状态。当线程需要更多寄存器时,它会使用 s_alloc_vgpr 指令请求新的 VGPR 数量。如果 s_alloc_vgpr 指令的调用值高于当前分配的数量,它就会尝试分配更多的寄存器;如果调用值低于当前分配的数量,它就会释放寄存器。更改 VGPR 分配会影响可用 VGPR 范围的上限,这与非动态 VGPR 分配的情况相同。硬件以 16 个或 32 个为一组分配 VGPR,具体取决于驱动程序如何设置 SQ_DYN_VGPR。一个线程最多可以分配 8 个块,所以如果一个线程需要使用超过 128 个 VGPR,驱动程序必须选择更大的块大小,并放弃一些分配粒度。
分配请求并不总是能成功。s_alloc_vgpr 会设置标量条件码(SCC)来表示成功,失败时则会清除它。SCC 类似于 CPU 上的标志寄存器,用于分支和带进位加法。着色器代码必须检查 SCC 来确定分配请求是否成功。如果分配请求失败,理论上着色器可以尝试找到其他有用的工作来做,同时定期重试分配。但这样做会相当复杂,所以实际上着色器会一直忙等待,直到分配成功。

在 DirectX 过程几何示例中使用动态寄存器分配的示例
因此,动态 VGPR 模式完全改变了占用率的问题。无论寄存器分配情况如何,一个 SIMD 可以拥有驱动程序所希望的尽可能多的活动线程。但理论上的占用率并不能说明全部情况。线程仍然可能会因为等待 VGPR 分配而被阻塞。一个 SIMD 可能所有的线程槽都被填满了,但其中一些线程可能在忙等待 VGPR 分配,而不是取得有用的进展。
死锁避免(Deadlock Avoidance)
忙等待(Busy-waiting )带来的问题可能不仅仅是性能上的不便。动态 VGPR 分配可能会导致死锁。AMD 知道这一点,并在 RDNA 4 的指令集架构手册中描述了这种情况是如何发生的。

不过,死锁的情况可能比 AMD 所描述的更普遍。如果一个 SIMD 中的每个线程都需要分配更多的寄存器,但硬件没有足够的空闲寄存器来满足任何请求,那么每个线程都会永远卡住。这就是一种死锁,即使从技术上来说还有可用的寄存器。

AMD 通过一种死锁避免模式来缓解一些死锁情况。指令集架构手册中对细节的描述很少,只是说它会始终保留足够的 VGPR,以使一个线程能够达到最大 VGPR 分配。每个线程最多可以分配 8 个 VGPR 块,并且每个线程槽会保留一个块,所以死锁避免模式会保留 7 个 VGPR 块。我们猜测死锁避免模式的工作原理是一次只允许一个线程从保留池中分配寄存器。简而言之:
基本情况:没有分配保留寄存器。任何请求都可以继续进行。
从(1)开始,所有线程的任何分配请求组合都将至少允许一个线程(比如线程 A)成功。
从(2)开始,没有其他线程可以从保留池中分配寄存器,从而允许线程 A 在需要时将其寄存器分配增加到最大值。
最终,A 会离开其高寄存器使用的代码部分,或者完全终止,从而释放寄存器供其他线程做同样的事情。
显然,这种情况对性能来说并不好,因为它可能会使线程之间的有用工作序列化。但慢慢到达终点总比根本到不了终点要好。

并且,如果程序员满足以下三个条件:
两个线程需要分配寄存器。
两个线程的高寄存器使用部分相互依赖,例如在生产者 - 消费者模型中。
在上述两个线程取得进展之前,没有其他线程可以放弃它们的寄存器。
那么即使启用了死锁避免模式,他们仍然可能会遇到死锁。程序员在动态 VGPR 模式下可能应该避免线程间的依赖关系,除非他们确信线程只在低 VGPR 使用部分相互等待。
动态 VGPR 模式的局限性和许多新功能一样,动态 VGPR 模式并不是一个万能的解决方案。它一开始的目标范围很窄,只能用于 wave32 计算着色器。像像素和顶点着色器这样的图形着色器只能使用常规的非动态启动模式。任何类型的 wave64 着色器也是如此。
以动态 VGPR 模式启动的一组线程工作集会 “接管” 相当于一个 GPU 核心的资源。在工作组处理器(WGP)模式下,这将是一个 WGP;在计算单元(CU)模式下,则是一个 CU。因此,动态线程和非动态线程不能在同一个 GPU 核心上共存。

用于指定各种计算程序启动参数的寄存器
动态 VGPR 模式在使用寄存器文件容量方面可能效率较低。每个启用的线程槽都会得到一个保留的 VGPR 块,无论该槽中是否实际运行着一个线程。如果一个工作负载没有足够的并行性来填满所有启用的线程槽,那么这些保留的寄存器就会被浪费。死锁避免模式会预留更多在非动态模式下可以轻松分配的寄存器。驱动程序可以通过禁用死锁避免模式或减少线程槽数量来减少保留的寄存器数量。但这两个选项都有明显的缺点。在 wave32 模式下,当前 RDNA 4 GPU 上的非动态寄存器模式可以在 24 个条目块中分配多达 256 个寄存器。这比在动态 VGPR 模式下为一个线程分配 256 个寄存器所需的 32 个条目块提供了更细的粒度。
英伟达的动态寄存器分配AMD 并不是唯一一家允许线程在执行过程中调整寄存器分配的 GPU 制造商。英伟达在 Hopper 架构中引入了 setmaxnreg PTX 指令,并且该指令在 Blackwell 消费级 GPU 中得以延续。setmaxnreg 表面上的作用与 AMD 的 s_alloc_vgpr 类似,允许调用线程请求不同的寄存器分配。然而,英伟达的动态寄存器分配与 AMD 的工作方式非常不同,或许更应该称之为寄存器重新分配。英伟达方面从未给这个机制起过名字。
英伟达不使用单独的启动模式。内核总是以常规方式启动,具有指定的寄存器分配,这也决定了它们可以同时运行多少个线程。例如,在 Blackwell 上使用 96 个寄存器的计算着色器,在每个流多处理器(SM)子分区中只能同时运行 5 个线程。线程启动后,它们可以调用 setmaxnreg 在同一个工作组中的线程之间转移寄存器。与 s_alloc_vgpr 不同,setmaxnreg 的寄存器池是工作组一开始所拥有的任何寄存器。如果每个线程都调用 setmaxnreg,并且线程之间请求的寄存器数量大于工作组一开始拥有的数量,那么无论寄存器文件可能有多少空闲空间,它们都会发生死锁。
setmaxnreg 是一个 PTX 指令。PTX 是英伟达 GPU 的一种中间级编程语言,具有类似汇编的语法。它不是汇编语言,英伟达将汇编语言称为 SASS。然而,PTX 旨在比类似 C 语言的高级语言对发出的指令提供更多的控制。因此,PTX 指令通常与 SASS 指令有相似之处,并且可以提供有关底层指令集架构的提示。

围绕 setmaxnreg 的语义表明,英伟达的机制是为了在线程之间进行紧密协调的寄存器交换。可以说,它不像 AMD 那种自由流动的动态分配行为,在 AMD 的机制中不同线程之间可能会不同步。英伟达的 “扭曲组(warpgroup)” 可能指的是共享同一个 SM 子分区,因而也共享同一个寄存器文件的线程。
“一个扭曲组中的所有扭曲(warp)都必须执行相同的 setmaxnreg 指令。在执行完一个 setmaxnreg 指令后,扭曲组中的所有扭曲在执行后续的 setmaxnreg 指令之前必须显式同步。如果扭曲组中的所有扭曲没有都执行 setmaxnreg 指令,那么行为将是未定义的。”
热情饱满的开发者可以通过在英伟达的一个工作组中分配一个 SM 中的所有寄存器文件容量,然后立即让每个线程将其分配削减到最小,来模拟 AMD 最初的动态 VGPR 状态。但在那之后,英伟达的同步要求将使得模拟 AMD 的独立分配行为变得困难。setmaxnreg 仅接受标量输入,这使得从内存中查找所需的分配值变得更加困难。当然,困难并不意味着不可能。通过充分应用条件分支可以模拟寄存器输入,但我们还是不要过多考虑这个问题了。

作为灵活性较低的交换,英伟达在同一个 SM 上混合 “动态” 线程和常规线程应该没有问题。英伟达还可以比 AMD 更精细地调整寄存器分配。后者尤其重要,因为英伟达的寄存器文件较小,只有 64 KB,“闲置” 寄存器文件使用造成的浪费可能会更加严重。
英伟达的寄存器重新分配机制不太适合 AMD 的光线追踪用例。然而,英伟达的光线追踪设计可能并不需要它。英伟达的硬件使用 DXR 1.0 光线追踪模型。如果它的工作方式与英特尔类似,光线追踪阶段将作为在 SM 上的单独线程启动来执行。在每个线程启动时进行的常规向量寄存器分配已经可以解决 AMD 在一体式光线追踪着色器中所面临的问题。
那么英特尔呢?英特尔的文档明确指出,光线追踪阶段作为单独的线程启动来执行。但即使他们没有这样说明,英特尔从动态寄存器分配中获得的好处也可能比 AMD 少。直到最近,英特尔的 GPU 一直使用固定的寄存器分配。每个线程无论是否需要,都会得到 128 个寄存器。像 Battlemage 这样的较新的 GPU 增加了一种 “大通用寄存器文件(GRF)” 模式,这种模式将占用率减半,为每个线程提供 256 个寄存器。没有中间选项。

英特尔的 Arc B580
因此,与 AMD 或英伟达相比,英特尔可以在每个线程拥有更高寄存器数量的情况下保持完全占用率。动态 VGPR 分配只有在首先有助于提高占用率的情况下才有用 —— 也就是说,如果 GPU 在非动态 VGPR 分配的情况下无法实现完全占用率。如果英特尔要动态分配寄存器,非常粗略的寄存器分配粒度可能会导致比 AMD 更多的线程被阻塞。
结语AMD 的动态 VGPR 分配模式是一个令人兴奋的新功能。它解决了 AMD 内联光线追踪技术的一个缺点,使 AMD 能够在不增加寄存器文件容量的情况下让更多的线程处于运行状态。这反过来又使 RDNA 4 在光线追踪工作负载中对延迟不那么敏感,而且可能只需要很少的功耗和芯片面积成本。使用超过 96 个 VGPR 的光线追踪着色器是动态 VGPR 功能的有吸引力的目标。

在 Radeon 图形分析器下对《雷神之锤 2 RTX》进行分析。尽管由于 VGPR 的使用,着色器被限制为 9 个线程(在 16 个槽中),但 AMD 选择使用完全内联的光线追踪着色器,并且没有使用动态 VGPR 分配。
AMD 上的光线追踪着色器可以选择内联所有光线追踪阶段,或者使用一种 “间接” 模式,在这种模式下,不同的阶段在单独的函数调用中执行。到目前为止,我只看到 AMD 在间接模式下使用动态 VGPR 分配。在这两种模式下,光线追踪阶段都在同一个线程内进行,但也许函数调用点提供了一个方便的地方来调整 VGPR 分配。毕竟,一个函数有明确定义的入口和出口点。AMD 常常更喜欢内联光线追踪阶段以避免函数调用开销。我还没有看到在光线追踪阶段内联时使用动态 VGPR 模式,即使在光线追踪着色器的占用率受到 VGPR 限制的情况下也是如此。

AMD 提供的 RX 9070
当然,s_alloc_vgpr 并不局限于函数调用点,所以未来 AMD 的驱动程序是否会更频繁地使用动态 VGPR 模式呢?不过,即使非动态分配可以实现完全占用率,AMD也会在间接模式下使用动态 VGPR 分配。这样做应该不会损害性能,但这确实表明目前驱动程序的决策还不够精细。

使用 AMD 的工具设置 “禁用光线追踪着色器内联” 会使驱动程序使用带有函数调用的光线追踪着色器,这些着色器也会使用动态寄存器分配。以此来说明对占用率的影响。
通用计算工作负载也可能从动态 VGPR 模式中受益,前提是 AMD 努力通过各种工具链来公开这个功能。英伟达的一些通用 GPU(GPGPU)库利用了 setmaxnreg,所以 AMD 的动态 VGPR 功能可能也有适用于计算的应用场景。
从更高的层面来看,像动态 VGPR 分配这样的功能表明 AMD 在 GPU 方面的努力正在快速推进。这感觉不是一个容易实现的功能。线程寄存器分配在物理寄存器文件中可能是非连续的,这使得底层的寄存器寻址变得复杂。像死锁避免这样的功能需要额外的工作。关于光线追踪,动态 VGPR 分配表明在 AMD 的单着色器光线追踪模型中还有很多可以改进的地方。除了打破错误的跨波内存依赖关系之外,AMD 似乎决心在每一代产品中不断消除性能限制因素。
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。
想要获取半导体产业的前沿洞见、技术速递、趋势解析,关注我们!
