3月24日晚,国内知名大模型平台DeepSeek悄然发布了V3模型的最新版本0324。与以往不同的是,此次发布异常低调,既未在国内公众号上宣传,也未在海外社交平台造势,而是直接将模型上传至HuggingFace平台,供用户下载使用。
据国外用户反馈,V3-0324的最大亮点在于其强大的代码生成能力。仅需简单的文本提示,模型便能快速生成网站和App的开发代码,其表现甚至可以媲美当前全球顶尖的闭源代码模型Claude 3.7 Sonnet的思维链版本。
与Claude 3.7 Sonnet相比,V3-0324不仅开源免费,还具备更高的推理效率,为用户提供了更具性价比的选择。这一发布无疑为开发者社区带来了新的工具和可能性。

开源地址:https://huggingface.co/deepseek-ai/DeepSeek-V3-0324/tree/main
有用户反馈,最新版本的V3模型展现出了令人惊叹的解题能力。在测试中,它仅用不到一分钟的时间便成功破解了一道复杂的密码谜题,展现出极高的效率。相比之下,Sonnet 3.7耗时约五分钟却未能完成同一任务。这一对比进一步凸显了V3在推理速度和问题解决能力上的显著优势。

中国在科技领域的崛起,得益于其庞大的人才储备和日益增强的创新实力。这一巨人的觉醒,不仅为中国自身的发展注入了强劲动力,也为全球科技进步带来了更多可能性。作为旁观者,我对此并不感到担忧,反而期待从中受益,见证更多卓越科技成果的诞生。
有网友推测,此次发布的DeepSeek V3很可能是对去年年底版本的一次迭代更新,类似于OpenAI对其模型的持续优化,而非完全重新设计。这种渐进式的改进方式在行业中并不罕见,正如GPT-4也经历了多次迭代但并未改变核心编号。
在实际应用中,DeepSeek V3相较于R1在创意写作任务中表现更为出色,其显著优势在于更快的处理速度。这种高效性使得用户能够迅速进行多次迭代,从而提升创作效率。至于模型可能产生的“幻觉”或准确性不足的问题,这并非不可克服的挑战,因为最终文本仍需经过人类的编辑和审核,以确保内容的质量和准确性。

DeepSeek的影响凸显了一个重要的技术转变。

有用户对V3-0324进行了快速评测,结果令人印象深刻:模型一次性生成了超过800行代码,成功开发了一个完整的网站,且全程未出现任何错务。作为一款免费开源的工具,V3-0324不仅展现了卓越的性能,还以惊人的速度完成任务。
这一表现再次证明了开源模型的强大潜力,它们正在为整个行业树立新的标杆。同时,开源技术的崛起也在无形中向大型科技公司施压,促使它们以更低的成本开发更优质的模型,从而推动整个领域的进步。这样的良性竞争无疑为技术创新和用户带来了更多可能性。

您的浏览器不支持 video 标签
最新版本的V3模型展现了其强大的编程能力,仅凭一条简单的提示便成功生成了一个现代化的登录页面。提示词为:“用HTML/CSS/JS编写一个现代化的登录页面,并将所有内容整合到一个文件中!”模型出色地完成了任务,将代码无缝融合,无需额外修改。
值得注意的是,DeepSeek-V3在编程能力上已经与Claude 3.7 Sonnet比肩,甚至在某些方面更具优势。作为一款无限制且完全免费的开源模型,它为用户提供了与顶尖商业模型相媲美的性能,同时降低了使用门槛,进一步推动了技术普惠。这一成就不仅体现了开源模型的潜力,也为开发者提供了更高效、更便捷的工具选择。

您的浏览器不支持 video 标签
我向最新版本的DeepSeek V3模型提出了一个挑战:仅用一个HTML/JS脚本,构建出最精美且复杂的动画效果。模型不负众望,成功生成了一个融合了丰富视觉效果和流畅动态的脚本,将所有功能整合在一个文件中,无需额外修改。

该网友进一步表示,他们正与未来进行交流,并对V3的编程能力感到非常满意。

V3简单介绍
V3作为一个庞大的专家混合模型(MoE),具备6710亿个参数,其中370亿参数在运算过程中处于活跃状态。与传统的大型密集神经网络模型不同,后者在处理每个输入标记时都需要激活所有参数,这无疑消耗了巨大的计算资源。
在专家混合模型的传统架构中,专家之间的负载均衡问题尤为突出。一旦出现负载不均,便可能导致类似交通堵塞的路由崩溃现象,进而阻碍数据在模型中的顺畅流通,严重影响计算效能。
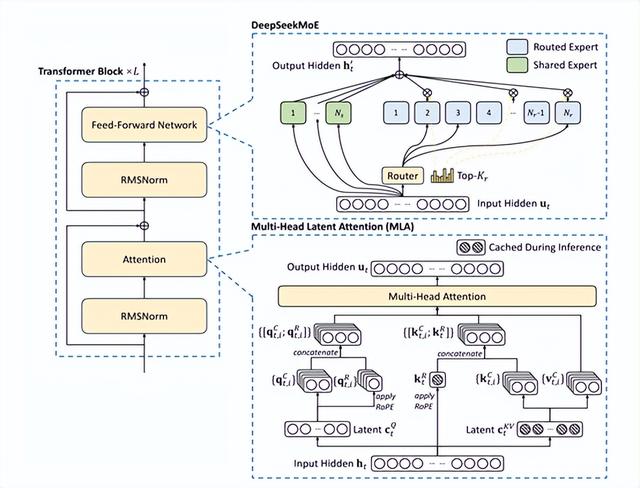
为应对传统专家混合模型中负载不均衡的挑战,通常采用辅助损失来调节负载。然而,这种方法存在潜在缺陷:过高的辅助损失可能对模型性能造成不利影响,犹如为缓解交通压力而施加过多管制,反而降低了整体通行效率。
DeepSeek在V3的设计中突破了常规,提出了一种无需辅助损失的负载均衡策略,创新性地引入了“偏差项”概念。在模型训练阶段,每个专家均被赋予一个偏差项,该偏差项会被整合至亲和力评分中,用以决定top-K路由的选择。
模型实时监控每一批训练数据中专家的负载状况。若某专家负载过高,类似桥梁承载过量车辆的情形,便相应调低其偏差项;若负载过低,则提高偏差项。这种动态调节机制使V3在训练过程中能够有效平衡专家负载,相较于单纯依赖辅助损失的模型,其性能获得了显著提升。
此外,V3还引入了节点受限的路由机制,以降低通信成本。在大规模分布式训练中,跨节点通信的开销往往成为性能瓶颈。通过限制每个输入最多只能被发送至预设数量的节点,V3显著减少了跨节点通信的流量,从而提升了训练效率。
这种路由机制不仅削减了通信开销,还使得模型在维持高效计算与通信重叠的同时,能够扩展到更多的节点和专家,进一步增强了模型的可扩展性和训练效能。
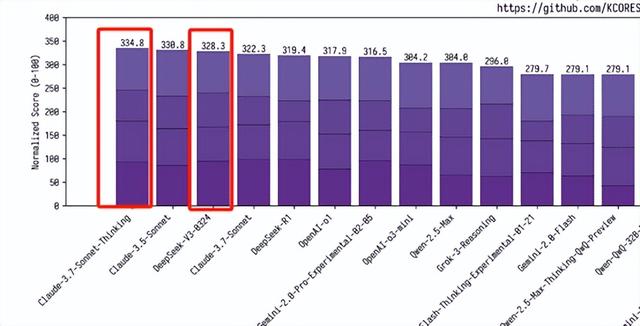
根据国际开源评测平台kcores-llm-arena的最新测试结果,V3-0324在代码能力评估中取得了328.3分的优异成绩,超越了普通版Claude 3.7 Sonnet的322.3分,并与思维链版本的334.8分表现相当接近。这一数据充分展示了V3在编程任务中的卓越实力。
·
我们相信人工智能为普通人提供了一种“增强工具”,并致力于分享全方位的AI知识。在这里,您可以找到最新的AI科普文章、工具评测、提升效率的秘籍以及行业洞察。
欢迎关注“福大大架构师每日一题”,让AI助力您的未来发展。
·
