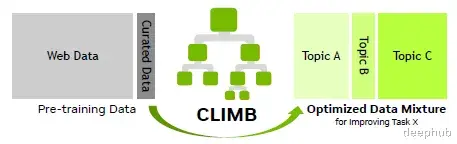
尽管优化预训练数据混合对大型语言模型(LLM)的性能有显著影响,但确定最优数据配比仍然是一个亟待解决的挑战。为应对这一问题,英伟达提出了一种名为CLIMB(CLustering-based Iterative data Mixture Bootstrapping)的自动化框架,该框架能够在预训练环境中系统地发现、评估并优化数据混合策略。CLIMB通过在语义空间中嵌入并聚类大规模数据集,并结合小型代理模型与性能预测器,迭代搜索最优数据混合比例。
技术创新点CLIMB框架主要贡献体现在以下三个方面:
提出了一种基于语义嵌入的数据混合方法,能够自动识别、分组并混合高质量的数据聚类,实现高效的领域特定训练,同时消除了对人工预定义领域标签的依赖。
设计了创新的迭代搜索机制,能够在训练过程中动态优化数据混合比例,平衡多样性与领域相关性,同时有效解决了数据聚类与过滤过程中的扩展性挑战。
构建了一个包含20个语义聚类、经过质量过滤的1.2万亿词元语料库,为数据混合研究提供了新的实验基础,并进一步提炼出一个高质量的4000亿词元预训练数据集。
框架整体架构CLIMB框架的整体结构如下图所示:

该阶段主要通过嵌入和聚类技术将原始数据进行预处理与分组。这些聚类构成了后续搜索空间的基础,其中混合策略被定义为一组用于组合不同聚类的权重向量。
混合自举阶段在第k次迭代中,CLIMB从可能的混合配置中采样nk个候选混合方案,对其中一部分进行代理模型训练,并更新性能预测器以估计所有候选混合的效果。预测器能够筛选出可能表现不佳的混合方案,确保只有最具潜力的配置能够进入后续迭代的完整代理训练评估。
最优混合权重确定通过逐步优化搜索空间并剔除次优候选方案,CLIMB最终收敛到经过优化的数据混合配比,有效平衡了模型的通用性能与领域特定能力,无需繁重的人工管理过程。
技术实现细节数据预处理流程数据预处理分为三个关键步骤:
文本嵌入处理
针对包含n个文档的大型原始数据集D̂ = {D₁, D₂, ..., Dₙ},采用嵌入模型Me将每个文档映射到语义空间,生成对应的嵌入向量集合E = {E₁, E₂, ..., Eₙ}。
嵌入聚类分析
利用k-means等聚类算法对嵌入向量进行聚类,将数据分组为Kinit个初始聚类。为确保后续处理的粒度足够细致,通常将Kinit设置为较大值(如1000)。
聚类优化与合并
基于质量指标进行聚类级别的剪枝,移除低质量聚类,保留Kpruned个高质量聚类。随后根据聚类质心之间的距离将相似聚类合并为Kenhanced个最终聚类,其中Kenhanced < Kpruned < Kinit。经过此过程,原始数据集D̂被精简为优化后的数据集D。
迭代自举:混合权重搜索双层优化问题建模
CLIMB将混合权重搜索视为双层优化问题:给定一组数据聚类D = {D₁, D₂, ..., Dₖ}和目标函数ℓ(α, ω),其中模型权重ω使用混合权重α进行训练,该函数输出在校准集上的性能P。目标是识别最优混合权重α* ∈ A,以最大化任务性能ℓ(α, ω)。
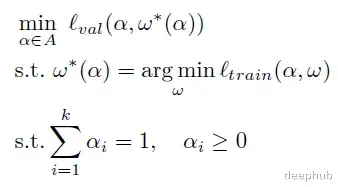
性能预测器近似目标函数
为降低计算成本,CLIMB引入预测器fθ(α),基于有限的(混合权重,性能)对来近似ℓ(α, ω),大幅降低训练开销。
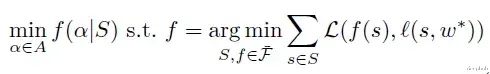
其中L是预测器fθ的损失函数,F̃表示ℓ的所有可能近似集合,S := {S ⊆ A | |S| ≤ C}表示满足采样预算C的所有配置集合。
迭代自举优化过程
CLIMB提出一种迭代方法来同步优化采样策略S和预测器fθ。数学上,这等效于使用坐标下降法解决双层优化问题,在优化配置采样和预测器拟合子程序之间交替迭代,第k次迭代可表述为:

其中TopN(P̃k)代表根据任务性能P̃k排名的前N个配置集合。
下图通过t-SNE可视化了CLIMB的迭代搜索过程,每个点代表搜索空间中的一个数据混合配置,不同迭代阶段(CLIMB-Iter1、CLIMB-Iter2、CLIMB-Iter3)展示了搜索空间随迭代优化的演变过程。

CLIMB的实现始于从配置空间A中随机采样初始配置并训练代理模型以获取性能指标,初始化采样集S₁。随后,在迭代k = 2,...,K中,交替优化采样集Sₖ和预测器fᵏθ。
配置采样子程序
在迭代k+1时,根据预测性能P̃k对权重空间A中的所有未采样配置进行排序。为平衡探索与利用,从排名前N的配置中随机采样M个新配置,与Sₖ组合形成Sₖ₊₁。
预测器拟合子程序
通过最小化损失函数L,使用Sₖ₊₁中的采样配置训练预测器fᵏ⁺¹θ。然后利用更新后的预测器评估配置生成预测性能P̃ₖ₊₁。
通过在预定迭代次数内交替执行这两个子程序,CLIMB能够逐步优化预测器并将搜索过程引导至更高质量的混合权重子空间,提升搜索结果的整体质量。最终,选择经最终预测器评估的最佳配置作为数据混合的最终权重。
实验评估与结果与现有数据混合方法的比较下表展示了CLIMB与其他数据混合基线方法的性能对比:
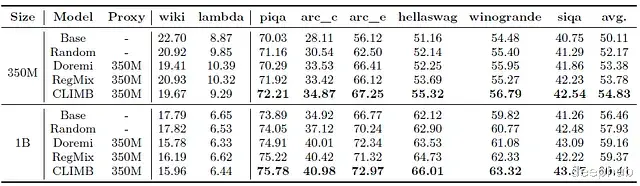
实验表明,CLIMB在350M模型上达到了54.83%的平均准确率,明显优于随机混合策略(52.17%)和此前最佳的Regmix方法(53.78%)。同样,在1B模型规模上,CLIMB的平均准确率为60.41%,同样超越了所有基线方法。
与SOTA语言模型的性能比较下表展示了CLIMB与当前最先进语言模型在通用推理基准上的性能对比:

在同等规模(约1B参数)的模型比较中,CLIMB在大多数通用推理基准测试中都显著优于其他模型,包括Llama-3.2和AMD-OLMo。总体而言,CLIMB获得了最高的整体平均分,比排名第二的Llama-3.2高出2.0个百分点,这一差距在统计上具有显著意义。
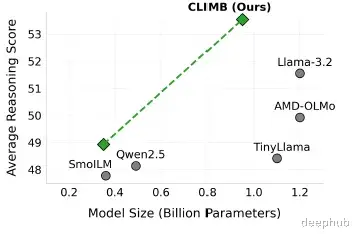
研究团队将CLIMB应用于Nemotron-CC和smollm-corpus两个现有数据集,旨在构建一个性能更强的预训练数据集。首先将这两个数据集合并,然后应用CLIMB聚类方法进行语义重组和质量过滤,将数据分为20个语义聚类,形成了一个包含1.2万亿词元的高质量语料库,命名为ClimbLab。
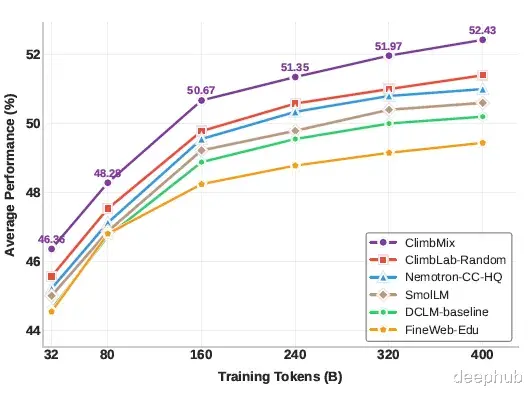
在此基础上,研究者利用CLIMB搜索算法从这些聚类中识别出最优的数据混合比例。基于此最优混合策略,进一步提取了一个名为ClimbMix的4000亿词元高质量数据集。为验证其效果,研究团队使用ClimbMix从头开始训练了一个1B参数规模的模型,并在相同词元预算条件下与其他数据集训练的模型进行比较。
如下图所示,在ClimbMix上训练的模型表现显著优于在现有公开数据集上训练的同等规模模型。这一结果充分证明了CLIMB框架在优化预训练数据混合方面的有效性。
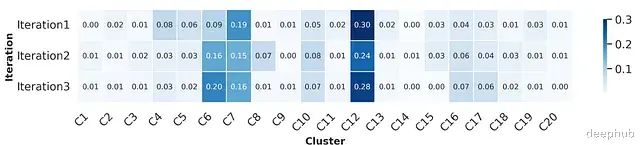
CLIMB算法识别出的最优数据混合权重分布如下图所示,该分布反映了不同语义类别内容在最终混合中的理想比例:
CLIMB框架是一种创新的基于聚类的迭代式数据混合自举方法,专为优化LLM预训练数据混合而设计。CLIMB通过自动化数据混合的发现、评估与优化过程,以明确的性能指标为目标改进了大规模预训练效果。
通过结合无监督聚类、代理模型训练和性能预测技术,CLIMB能够高效地探索庞大的数据组合空间,无需依赖预定义的领域标签或大量人工干预即可构建最优的领域感知混合策略。实验结果表明,使用CLIMB优化的数据混合训练的350M和1B参数规模模型,在12项推理任务上均达到了当前最先进的性能水平。
论文:https://avoid.overfit.cn/post/a326f45fca2f4e90828526ed568ee620
SACHIN KUMAR
