
大型语言模型(LLM)的进步令人瞩目,但如何进一步提升它们的推理能力仍然是一个关键挑战。
强化学习(RL)已成为LLM后训练阶段的重要方法,获取准确的奖励信号却是一个难题。
DeepSeek与清华大学的研究者合作发表了一篇论文,探索通过增加推理计算资源来提升奖励建模能力的新途径,为LLM推理能力的提升带来了新的曙光。
强化学习在提升LLM推理能力方面展现了巨大潜力,但如何获得准确的奖励信号,尤其是在多样化的领域中,仍然是一个挑战。
这篇论文的核心在于探究奖励模型(RM)在推理阶段的可扩展性,即能否通过增加推理计算资源来提升RM的性能。
研究者发现,点式生成式奖励建模(GRM)具备推理阶段可扩展的潜力,并提出了一种名为自我原则点评调优(SPCT)的学习方法。
SPCT方法的核心在于训练GRM生成具备可扩展奖励能力的行为。
它包括两个阶段:拒绝式微调和基于规则的在线强化学习。
拒绝式微调阶段旨在使GRM适应不同的输入类型,并生成正确格式的原则和点评内容。
研究者巧妙地采用了点式GRM,使其能够灵活处理不同数量的回答。

为了提高预测奖励的准确性,他们引入了提示式采样技术。
在SPCT的第二阶段,基于规则的在线强化学习被用于进一步微调GRM。
通过在线优化生成的原则和点评内容,GRM能够更准确地区分最优回答,从而提升推理阶段的可扩展性。
这种方法的优势在于能够无缝对接任何偏好数据集和标注的LLM回答,具有很强的通用性。
这项研究的一个重要创新点在于将“原则”从理解过程解耦,转变为奖励生成的一部分。

这意味着原则不再是预先定义的,而是根据输入问题和回答动态生成的。
这种转变使得奖励生成过程更具适应性,也为推理阶段的可扩展性提供了关键支撑。
通过对GRM进行后训练,生成的原则和点评内容的质量和细致程度都能得到进一步提升。
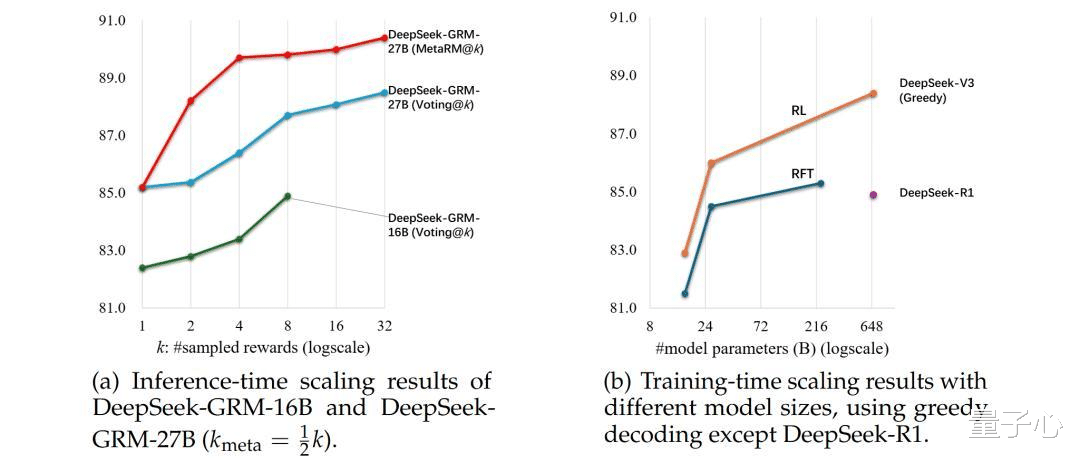
为了进一步提升DeepSeek-GRM的性能,研究团队探索了推理时扩展策略。
他们提出了通过生成奖励进行投票的方法,通过多次采样并整合奖励结果,提升最终奖励的质量和细腻度。
为了避免采样过程中出现偏差,研究人员还引入了元奖励模型(meta RM)来引导投票过程,过滤掉低质量的样本。
DeepSeek和清华的研究者基于Gemma-2-27B,经过SPCT训练,提出了DeepSeek-GRM-27B模型。
实验结果表明,DeepSeek-GRM-27B在多个综合RM基准测试中表现出色,超过了现有方法和模型。
尤其是在推理时扩展方面,DeepSeek-GRM-27B展现出显著的优势。
研究者还将DeepSeek-GRM-27B与更大规模的模型进行了比较,发现推理时扩展策略比单纯扩大模型规模更有效。

消融研究进一步验证了SPCT方法中各个组件的有效性。
研究结果表明,即使没有使用拒绝采样的评论数据进行冷启动,经过在线强化学习后,GRM的性能也能得到显著提升。
此外,原则生成对DeepSeek-GRM-27B的性能至关重要。
DeepSeek和清华的这项研究为提升LLM推理能力提供了一种新的思路。
通过增加推理计算资源,并采用SPCT等创新方法,可以有效提升奖励模型的性能。

这为未来LLM的发展和应用开辟了新的可能性。
这项研究也引发了一些值得思考的问题:推理时扩展策略的普适性如何?
在其他类型的LLM上是否也能取得类似的效果?
如何进一步优化SPCT方法以提升其效率和性能?
这些问题都有待进一步研究和探索。


deepseek伟大[点赞]