
那晚的大风夜里,有人刷着手机,看到一个视频传开:波士顿动力的机器人竟然在表演体操。
那个动作,一看就是经过了高水平的训练,但背后的训练方法让人充满好奇。
机器人到底怎么学会这些动作的?
传统编程能做到吗?
波士顿动力与RAI研究所合作,强化学习助力Atlas这事还得从波士顿动力这个在机器人界早已名声大噪的公司说起。
最近,他们搞了个大新闻,宣布与RAI研究所合作,共同推进机器人技术。
有人可能会问,RAI研究所是谁?
嗯,它的执行董事Marc Raibert其实是波士顿动力的创始人,这让我忍不住在心里偷笑,这种组合就像是天生的一对。
共同目标还不仅是开垦新技术,他们重点放在了强化学习这一领域。
想象一下,一个机器人不再是通过傻瓜式的预编程行动,而是通过类似人类学习的方式,不断摸索和调整自己的动作。

这就是强化学习的厉害之处。
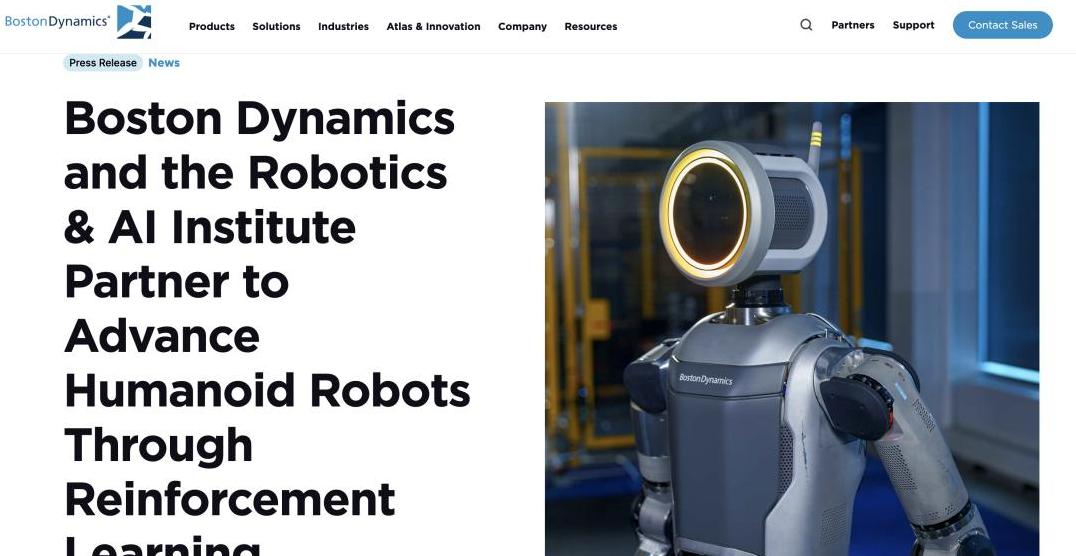
强化学习让机器人动作更自然波士顿动力的视频中,电动Atlas的表现真是令人印象深刻。
它不仅会走会跑,还会翻跟头,甚至像人一样爬行。
这些复杂动作的流畅度和自然性,简直是个惊艳的突破。
究其背后,是强化学习的加持。
这种学习方式就是借鉴了人类的行为模式。
比如,有了人类动作捕捉数据和动画数据,机器人可以通过这些参考来调整自己的动作,就像小孩子模仿大人一样,不断试错,慢慢把动作做到自然流畅。
这样一来,它们的动作不再只是机械执行预编程序,而是真正地在学习和适应环境。
从模拟到现实,1.5亿次试错练就完美动作说起训练过程,那可是相当硬核的。

RAI研究所的专家们设定了一个物理模拟器,通过这个模拟器,生成了大量的训练数据。
每一次模拟运行,就像是一场逼真的排练,机器人在这个虚拟世界里经历了大约1.5亿次的“试错—反馈—调整—再试”的循环。
不仅如此,这套控制策略还能跟踪并调整重定向的人类运动数据。
这就是说,机器人不仅需要学会动作,还要学会如何在不同的环境下执行这些动作。
这种能力在未来的实际应用中,无疑充满了各种可能性。
DeepSeek-R1的案例解密强化学习原理要深入理解强化学习,不妨看看DeepSeek-R1的案例。
这个名字乍听有点硬,其实理解起来并不难。
就像你第一次玩《超级马里奥》一样,什么都不懂,但可以乱按键,试试看——走几步,跳一下,碰到怪物——被打倒,再来。
通过这些尝试和错误,你最终明白了如何玩这个游戏。
一切都基于不断的反馈和调整。
这种“试错+奖励”的学习方式,就是强化学习的核心。
可以对比下小孩学吃饭的情景:第一次弄得一团糟,但每次把食物成功送入嘴里,家长都会给与鼓励。
最终,小孩在尝试和奖励中,学会了使用勺子的方法。
这在机器人领域也是同样的道理。
结尾:电动Atlas的新技能展示,不仅是科技的一次突破,更是一次观念的刷新。
通过强化学习,它不再是一个冰冷的机械,而是一个能在复杂环境中不断自我调整、进化的“生命体”。
这给未来带来了无限的想象和期待。
波士顿动力与RAI研究所的合作,无疑将成为机器人界的新标杆。
他们的探索和努力,终于让机器人不再停留在科幻电影中的桥段,而是逐步走进我们的生活。
未来,我们或许会看到更多这样的机器人,它们将不仅仅是人类的助手,更是我们的同伴,在这个科技与现实交织的时代,共同迎接未知的挑战。

