
这两天本该成为 AI 圈焦点的 Meta 新一代大模型 —— Llama 4,如今随着时间的流逝,逐渐被质疑声淹没:有人指责 Llama 4 在训练测试集上“作弊”,更有内部员工爆料称:“内部模型的表现实际未能达到开源 SOTA(当前最佳),甚至与之相差甚远,但是为了赶在 4 月底的 Deadline 之前交差,团队最终‘拼出了一个看起来还行’的版本”,该员工因无法接受这种结果,选择拒绝署名,并愤然离职...
尽管争议不断,但在 Meta 看来,Llama 4 依然是其在多模态 AI 模型探索上的重要一步。那么,这一代 Llama 到底带来了哪些技术突破?三款模型之间又各有怎样的定位?不妨先一起深入了解下 Llama 4 系列的全貌。
 Meta 发布 Llama 4 家族,官方号称“原生多模态 AI 创新的新时代开启”
Meta 发布 Llama 4 家族,官方号称“原生多模态 AI 创新的新时代开启”过去,在强大的 DeepSeek 系列还没开源之前,Meta 的 Llama 一直是开源大模型界的“天花板”。Meta 自己在发布新模型之际也强调说:“既然 AI 越来越多地走进人们的生活,那先进的模型就该向所有人开放,让每个人都有机会打造属于自己的 AI 体验。”
这次 Meta 正式发布了全新的 Llama 4 系列模型,一次性带来了三款重量级大模型选手:
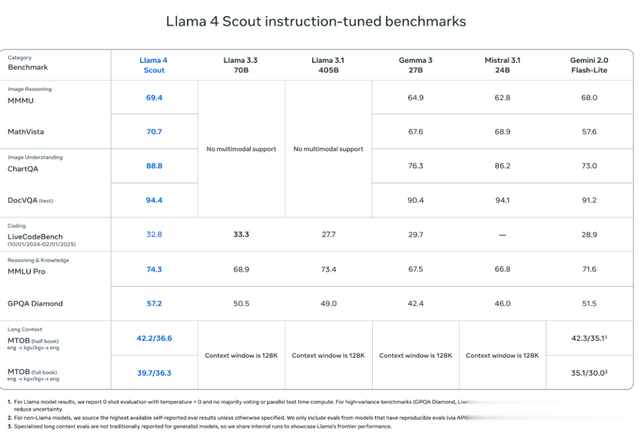
Llama 4 Scout:这是一个拥有 170 亿个“活跃参数”、使用 16 个专家模型的多模态 AI 模型。Meta 称,它是当前这个级别中全球最强的模型,不仅比以往所有 Llama 模型都更强大,还能在单个 NVIDIA H100 显卡上运行。而且,它支持 10M 上下文长度,比 Gemma 3、Gemini 2.0 Flash-Lite、Mistral 3.1 等主流模型在很多测试中表现更好。Llama 4 Maverick:同样是 170 亿活跃参数,但用了更多的专家模型(多达 128 个)。它在多个测试中表现超过 GPT-4o 和 Gemini 2.0 Flash。Meta 表示,在逻辑推理和编程任务上,它甚至能与 DeepSeek V3 打了个平手——而参数只有 DeepSeek V3 的一半。这些优秀的模型都来自一个“老师模型”——Llama 4 Behemoth,它有 2880 亿活跃参数,采用了 16 个专家,是目前最强的模型之一。它在数学、科学等标准测试中击败了 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro。不过,这款模型还处于预览阶段。而前面两款模型可以直接在 llama.com(https://www.llama.com/llama-downloads/)和 Hugging Face(https://huggingface.co/meta-llama)下载体验。

 Llama 4 Scout 和 Llama 4 Maverick 的亮点
Llama 4 Scout 和 Llama 4 Maverick 的亮点根据 Meta 官方博客介绍,新的 Llama 4 模型是其首批使用专家混合结构(Mixture of Experts,简称 MoE)的模型,和 DeepSeek V3 使用的架构一样。通俗地讲,MoE 不是所有的“脑细胞”都一起工作,而是输入一个字时,只调用一小部分“最擅长”处理它的模块。这样既聪明又节省计算资源。
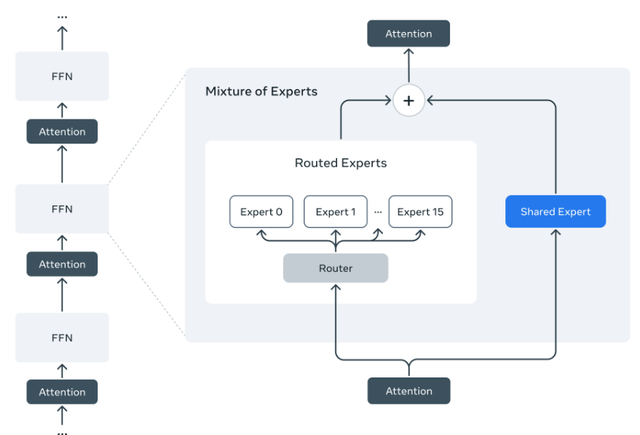
举个例子,Llama 4 Maverick 这个模型虽然总共有 4000 亿个参数(可以理解为模型“知识量”),但实际在运行时只启用了 170 亿个参数(称为“活跃参数”)。它是怎么做到既拥有庞大的“知识库”,又不耗太多算力的?秘诀就在于使用了 MoE 的设计。
在 MoE 层中,有 128 个路由“专家”和一个共享专家。每次处理一个文字或图像单元(token)时,模型只会调用这 128 个路由专家中的一个,加上共享专家,而不是调用全部专家。虽然 4000 亿个参数都存在显存里,但每次只用很少的一部分,大大提升了运行效率,降低了成本和响应时间。这意味着 Llama 4 Maverick 也可以在一台 NVIDIA H100 的服务器上顺畅运行,不用部署超级计算机。
此外,Llama 4 是从一开始就设计为可以同时理解文字和图像(甚至视频帧)的“多模态模型”。它采用了 Early Fusion(早期融合) 的技术,让文字和视觉信息在模型内部融合得更早更自然,不再是后期再拼接进来的。这种方式允许模型在训练时同时学习海量的文字、图片和视频内容,也提高了模型对图像内容的理解力。
为了更好地训练这样复杂的大模型,Meta 团队还发明了一个新的训练方法叫做 MetaP,用来优化模型的重要“超参数”(比如学习率、初始化方式等),提高了训练的稳定性和效果。
官方透露,Llama 4 通过对 200 种语言进行预训练来实现开源微调工作,其中包括 100 多种语言,每种语言都有超过 10 亿个 token。总体而言,相比 Llama 3,这次使用的多语言数据量增加了 10 倍。
与此同时,在训练过程中,Meta 使用了 FP8 精度的方法,可以在不牺牲模型质量的前提下大幅降低计算资源消耗。Meta 表示,在训练超大模型 Llama 4 Behemoth 时,使用了 3.2 万张 GPU,每张卡可以达到 390 TFLOPs 的计算效率。
在初步训练之后,Meta 还对 Llama 4 系列进行了中期、后期训练,专门用一些“长上下文”的训练数据,来让模型更擅长处理长文本,比如 Llama 4 Scout 支持长达 1000 万个 token 的上下文长度。
整体而言, 根据 Meta 公开的基准测试结果来看,在编码、推理、多语言、长上下文和图像基准测试中,Llama 4 Maverick 超越了 GPT-4o 和 Gemini 2.0 等同类模型,并且在编码和推理方面可与规模大得多的 DeepSeek v3.1 相媲美。

Llama 4 Scout 则是将上下文长度从 Llama 3 的 128K 大幅提升至 1000 万 token,这为多文档总结、分析海量用户行为以完成个性化任务、以及处理庞大的代码库等应用场景打开了全新的可能性。Llama 4 Scout 在预训练和微调阶段都使用了 256K 的上下文长度,这使得基础模型具备了出色的长文本泛化能力。

Llama 4 Scout 在编码、推理、长上下文和图像基准方面也超越了同类模型,并且比所有以前的 Llama 模型都具有更强大的性能。
 Llama 史上最大模型:Behemoth(巨兽)
Llama 史上最大模型:Behemoth(巨兽)Meta 这次还首次公开了 Llama 4 Behemoth 模型的预览版本,它也被称之为“教师模型”。
它同样是一款 MoE 模型,拥有 2880 亿活跃参数、16 个专家模型,参数总量接近 2 万亿,在数学、多语言和图像等非推理类基准测试中均表现出色,达到当前同类模型的前沿水平。
值得一提的是,Llama 4 Behemoth 不只是一个“大力出奇迹”的模型,它还承担了更深层次的“教师”角色 —— Meta 将其用于训练和“蒸馏”更小型的 Llama 4 模型(如 Maverick),显著提升了学生模型在多个终端任务中的表现质量。
为此,Meta 开发了一个全新的蒸馏损失函数,能够动态调整“软目标”和“硬目标”的权重,在整个训练过程中实现更精准的知识迁移。此外,为降低训练过程中的计算资源消耗,Meta 在 Behemoth 的预训练阶段进行了协同蒸馏(codistillation),将原本代价高昂的前向计算摊平到整个训练流程中。对于新增数据,则额外在 Behemoth 上执行前向计算以生成蒸馏目标。

 广泛关注背后的争议
广泛关注背后的争议最后,和以往 Llama 模型一发布就引发热议一样,Llama 4 的推出同样吸引了广泛关注。然而,不少用户在实际体验后却感到失望,认为它的真实表现并没有达到 Meta 宣传中所描绘的那般“划时代”。
X 用户 @deedydas 发帖称,「Llama 4 实际上似乎是一个糟糕的编码模型。 Scout (109B) 和 Maverick (402B) 在 Kscores 编码任务基准测试中的表现 4o、Gemini Flash、Grok 3、DeepSeek V3 和 Sonnet 3.5/7。LMarena 上的 ELO-maxxing 分数再高,也不能掩盖模型本身的问题。」

随即,他还附上了 Kscores 的(https://github.com/KCORES/kcores-llm-arena/)测试结果,该基准是用来评估大模型在实际编程场景中实用性的一个重要指标。在这个测试中,Llama 4 Scout(17B 16E)在编码能力方面明显不如 DeepSeek V3。

不仅如此,另一位用户@flavioAd 尝试用完全相同的提示词对比测试了 GPT-4o 和 Llama 4。不难看出,GPT-4o 生成的内容有不少瑕疵,但是还是比 Llama 4 要稍微好一些。

有 Reddit 用户甚至调侃:“还记得当初 DeepSeek 发布时,就有传言称 Meta 内部因此感到紧张,相比之下,其 Llama 4 的表现太让人失望了,以至于 Meta 一度犹豫要不要发布它吗?现在看来,他们也许真的应该跳过这一代,直接上 Llama 5 才对...”
还有网友爆料,“他们确实放弃了原来的 Llama 4,然后再次尝试使用 Deepseek 的架构,才有了现在的 Scout 和 Maverick。”
在争议持续发酵之际,一位自称是 Meta 内部员工的用户 “dliudliu” 在一亩三分地社区发文,披露了 Llama 4 背后的更多细节。他写道:
在经过反复训练,其实内部模型的表现依然未能达到开源 SOTA,甚至与之相差甚远。
然而,Meta 高层建议将各个 benchmark 的测试集混合在 post-training 过程中,目的是希望能够在各项指标上交差拿出一个“看起来可以”的结果。而如果未能在 4 月底的设置的 deadline 前达成目标,后果将不堪设想。
昨日,Llama4 发布之后,X 和 Reddit 上已经有很多人实测结果非常差。
作为一名目前也在学术界的人,我实在无法接受这种做法。因此,已经提交离职申请,并且明确表示之后 Llama4 的 Technical Report 中不要署上我的名字。Meta 的 VP of AI 也是因为这个原因辞职的。
回看本月初,据外媒报道,Meta 人工智能研究副总裁、也曾重度参与过 Llama AI 的 Joelle Pineau 在任职 8 年后离职。一切也都和这位自称 Meta 内部员工的表述对得上。

与此同时,评论区也有网友表示,“作为之前在 Meta 实习过的人,这是真的。我不想说太多,但 GenAI 组织很乱,管理层没有整合模型的经验,而且会因为政治原因而争吵设计决策。非常糟糕的团队,浪费了大量的计算资源。”

倘若为真,那 Llama 4 表现不佳的情况也就不难理解了。

最后,还有网友犀利点评道,「Llama 4 的 Scout 和 Maverick 两款模型让我大失所望。也许这也能解释为什么 Meta 的 AI 研究负责人 Joelle Pineau 最近会被解雇。
这些模型为何如此平庸?问题可能出在它们的“专家混合”架构中用了太小的专家模型——只有 170 亿参数?放在今天这个时代,确实显得有些“小”。
Meta 的困境也说明了一个现实:就算你手握全球最多的 GPU 和数据,如果没有新鲜的点子,也未必能造出领先的 AI。反倒是像 DeepSeek、OpenAI 这样的公司,真正靠创新在推动 AI 向前。AI 不是靠砸资源就能搞定的活儿,它最终拼的,还是脑子。」

至此,Llama 4 你用上了吗?你觉得它是否名副其实,还是确实有些“货不对板”?欢迎留言分享你的体验和看法。
参考:
https://ai.meta.com/blog/llama-4-multimodal-intelligence/
https://www.reddit.com/r/LocalLLaMA/comments/1jt7hlc/metas_llama_4_fell_short/
https://x.com/deedydas/status/1908749649642663959/photo/1
https://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=1122600&page=1&authorid=1241854
