DeepSeek 以其强大的功能和开源特性吸引了众多目光。对于普通人而言,若想充分挖掘 DeepSeek 的潜力,本地部署不失为一种好方法。它不仅能摆脱在线版本的限制,还能满足个性化需求。本文将为大家详细介绍如何低成本地在本地部署 DeepSeek。
一、为什么要本地部署 DeepSeek突破在线限制:在线版本的 DeepSeek 常常遭遇 “服务器繁忙” 的状况,每天能获取的回答次数有限。比如很多用户反映,在使用高峰期,提问后经常长时间得不到回复 ,而本地部署则可以随时使用,不再受服务器状态的制约。
实现灵活定制:个人可以根据自身硬件资源和实际需求,自由调整 DeepSeek 的配置参数。就像图像设计师,能够依据自己电脑的显卡性能,选择合适的图像识别或生成模型版本,减少 “幻觉” 的产生,提升使用效果。
保障数据自主:在本地部署后,用户可以完全自主地管理本地数据,包括数据的存储、备份、删除等操作,方便对数据进行二次开发和利用,不用担心数据隐私泄露问题。
二、本地部署前的准备(一)硬件要求显卡:这是影响 DeepSeek 运行速度和性能的关键硬件。如果显卡性能不足,模型运行会非常缓慢甚至无法运行。例如,若想运行 7B 或 8B 的模型,建议配备 GTX 1060(6GB)及以上的显卡,RTX3060 及以上则更佳;要是运行 14B 的模型,最好有 12 核 CPU、32GB 内存以及 16GB 显存 。
内存:内存容量也不容忽视,8GB 内存是基本要求,推荐使用 16GB 及以上内存,以保证模型运行的流畅性。
存储空间:C 盘至少需要剩余 20GB 的空间,为了获得更好的性能,建议使用 NVMe 固态硬盘。
(二)部署工具选择LM Studio:这是一款专为本地运行大语言模型设计的客户端工具,支持多种开源模型,提供简单易用的界面,用户无需编写复杂代码就能加载和运行模型,其 “本地化” 特性还能确保数据的隐私和安全。
Ollama:也是一个不错的选择,支持主流操作系统,如 macOS、Linux 和 Windows。在 Ollama 中搜索选择 DeepSeek 模型,即可完成在本地电脑上的部署,操作相对简单。
三、模型选择要点DeepSeek 发布了不同参数量的模型,参数规模以 B(Billion,十亿)表示 。数值越高,模型越复杂,理解和生成能力越强,但对系统性能要求也越高,生成内容的速度会越慢。
1.5B 模型:文件较小,大约 3GB,适合初次体验和尝鲜,但性能相对较弱,不太推荐用于实际应用。
7B 模型:适合普通内容创作及开发测试场景,文件大小提升至 8GB,推荐搭配 16GB 内存 + 8GB 显存,能满足大多数用户的日常需求。
8B 模型:在 7B 的基础上更精细一些,适合对内容要求更高更精的场景,同样适合大多数普通用户。
14B 模型:文件大小提升至 16GB,建议配置 12 核 CPU + 32GB 内存 + 16GB 显存,适合专业及深度内容创作场景。
四、基于 LM Studio 的部署步骤安装 LM Studio 客户端:在官网lmstudio.ai下载对应操作系统的安装包,下载完成后双击运行,按照提示完成安装。安装完成后启动 LM Studio。

设置语言:进入 LM Studio 后,点击右下角的设置图标(小齿轮),将语言改为简体中文,方便后续操作。

加载模型:
自行下载模型:如果能自己找到各种不同版本的模型,下载到本地后,点击左上方文件夹的图标,选择模型目录导入即可。这种方式的优点是可以选择自定义的模型,而且下载速度有保障。
在 LM Studio 中搜索下载:在 LM Studio 的设置里,常规部分选中 Use LM Studio's Hugging Face 的复选框,然后点击左上方的搜索图标(放大镜),搜索 deepseek 即可找到各种不同版本的模型。该方式使用简单,但下载可能不太稳定。
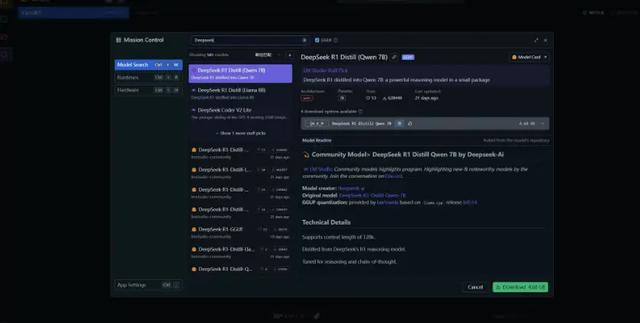
温馨提醒:如果硬件不是很强,不要犹豫,选在1.5b就行,处理一些简单的需求是没有问题的。如果硬件还可以,比如有着16GB内存、RTX3060的独显,那么可以选择7b或8b,14b也能运行,不过生成速度会慢一些,大约1秒能生成5个字左右;如果硬件很强,比如有着128GB内存、RTX5090D显卡,可以选择14b、32b,或者试试70b。
五、基于 Ollama 的部署步骤1.安装 Ollama:打开 Ollama 官网ollama.com,点击 “Download”,根据本地电脑的操作系统类型下载对应的 Ollama 版本并完成安装。安装完ollama框架后,用win键+R键呼出运行,输入cmd打开命令行窗口,输入ollama,出现命令菜单就是安装成功了。

2. 运行 Ollama:确保电脑上已经运行 Ollama,以 Mac 为例,在顶部菜单栏中看到小羊驼图标即表示运行成功。
3. 搜索并选择模型:在 Ollama 官网搜索 “deepseek” ,点击 deepseek - r1,会出现多个不同大小的模型版本,根据自己的硬件配置选择合适的模型。

4. 运行模型:确定好想要的模型后,复制对应的命令到终端并执行。例如,运行 1.5B 模型,在终端输入 “ollama run deepseek - r1:1.5b” ,然后等待进度条 pulling manifest 下载到 100% 即可开始使用。
六、常见问题及解决方法下载速度慢:使用 LM Studio 时,可以通过修改配置文件,将默认的 Hugging Face 镜像替换为国内镜像;使用 Ollama 下载模型卡顿的话,可以关掉命令行窗口再重新粘贴代码,通常会继续满速下载。
模型加载失败:确保模型文件的扩展名为.gguf,并检查 LM Studio 或 Ollama 是否为最新版本。
运行速度慢 / GPU 未调用:确认已安装最新的 CUDA 驱动,并重启 LM Studio 或相关程序;如果是硬件配置不足,可以尝试降低模型参数规模。
通过以上步骤和方法,普通人也能低成本地在本地部署 DeepSeek,开启属于自己的 AI 探索之旅。赶紧动手试试吧,利用 DeepSeek 为工作和生活带来更多便利和创新。

直接跨越阶层
调衣食住行一系列
没得意思了。都和你们说了 调控任意目标群体 想调财富 调姻缘 调工作顺利一系列 浪费时间
不同人群需求不一样
必须是新版技术新版产品新版创新一系列
我听歌曲的
调柴米油盐酱醋茶
几舒服哦
有山有水环绕
不看不听不想
其实我真的觉得 找块风水宝地 郊区一两公里就可以了 世外桃源与世无争
找个真正赚过大钱 又有技术又有人脉 思想觉悟又高的人带个队就解决了
调点新科技指数 调点农民幸福指数
这个顶级知识 懂不懂
免税一系列