
学境思源,一键生成论文初稿:
上周五,DeepSeek 宣布本周将是开源周(OpenSourceWeek),并承诺连续开源五个软件库。昨天,他们开源了第一个代码库 —— FlashMLA,一款用于 Hopper GPU 的高效型 MLA 解码核,仅用了 24 小时就达到了接近 8k 的 star 量。

今天,DeepSeek 继续开源底层架构的创新,发布了首个用于 MoE 模型训练和推理的 EP 通信库 DeepEP。
 DeepEP 是什么?
DeepEP 是什么?DeepEP 是一个专为混合专家系统(MoE)和专家并行(EP)定制的通信库。它提供高吞吐量和低延迟的 all-to-all GPU 内核,这些内核也被称为 MoE 分发和合并。该库还支持低精度操作,包括 FP8。
在分布式系统中(如多 GPU 训练环境),所有处理单元之间需要高效地传递数据。在 MoE 中,这点尤为重要,因为不同「专家」需要频繁交换信息。并且 MoE 模型容易在「专家并行」中出现负载不均衡,导致每个「专家」分到的算力不均,不重要的「专家」难以发挥应有的性能。
此次开源的 DeepEP 做到了:
高效优化的 All-to-All 通信支持 NVLink 和 RDMA 的节点内 / 跨节点通信训练及推理预填充阶段的高吞吐量计算核心推理解码阶段的低延迟计算核心原生支持 FP8 数据分发灵活控制 GPU 资源,实现计算与通信的高效重叠高效通信减少了数据传输的瓶颈,计算核心的优化提升了处理速度,灵活的资源调度让计算和通信不互相等待。
DeepEP 的性能如何?DeepSeek 在 H800 上测试常规内核(NVLink 最大带宽约 160 GB/s),每个 H800 连接到一个 CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约 50 GB/s)。他们遵循 DeepSeek-V3/R1 预训练设置(每批次 4096 个 token,7168 隐藏维度,top-4 组,top-8 专家,FP8 分发和 BF16 合并)。
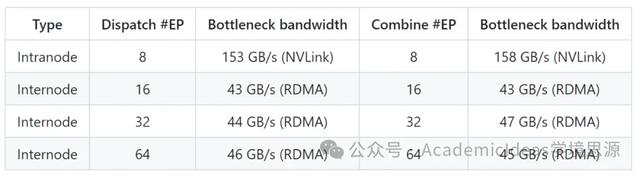
对于低延迟内核,DeepSeek 在 H800 上测试,每个 H800 连接到一个 CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约 50 GB/s)。他们遵循典型的 DeepSeek-V3/R1 生产设置(每批次 128 个 token,7168 隐藏维度,top-8 专家,FP8 分发和 BF16 合并)。
 DeepEP 如何加速学术研究
DeepEP 如何加速学术研究DeepSeek 的开源项目不仅推动了 AI 基础设施的技术边界,还为学术研究提供了强大的工具。最新开源的 DeepEP,作为一款专为混合专家系统(MoE)和专家并行(EP)优化的通信库,为我们提供了高效的计算和通信能力,极大地加速了复杂模型的训练和推理过程。对于从事 AI 研究的学者和工程师来说,DeepEP 不仅是一个技术突破,更是一个能够显著提升研究效率的工具,帮助他们在论文写作和发表过程中节省大量时间和资源。
DeepEP 为论文写作带来的优势加速模型训练与推理
DeepEP 通过高效的 All-to-All 通信和优化的计算核心,显著减少了模型训练和推理的时间。对于 MoE 模型来说,传统的通信瓶颈往往会导致训练时间过长,尤其是在多 GPU 环境中。DeepEP 支持 NVLink 和 RDMA 的节点内/跨节点通信,能够充分利用硬件资源,最大限度地提升数据传输效率。这意味着可以在更短的时间内完成实验,快速验证模型的有效性,从而加速论文的写作进程。
支持低精度计算,降低资源消耗
DeepEP 原生支持 FP8 数据分发,这是一种低精度计算格式,能够在保证模型性能的同时大幅降低计算资源的消耗。对于学术研究者来说,计算资源往往是有限的,尤其是在没有大规模 GPU 集群支持的情况下。DeepEP 的低精度计算能力能够在有限的资源下运行更复杂的模型,从而在论文中展示更具创新性的研究成果。
灵活的 GPU 资源调度
DeepEP 提供了灵活的资源调度机制,能够实现计算与通信的高效重叠。这意味着在模型训练过程中,GPU 的计算和通信任务可以并行执行,避免了资源闲置和等待时间。对于论文写作来说,这种高效的资源利用方式不仅缩短了实验周期,还降低了研究成本,使得我们能够更快地完成数据分析和结果验证。
优化推理解码阶段的延迟
在论文写作过程中,模型的推理性能往往是需要重点展示的部分。DeepEP 提供了低延迟的推理解码内核,特别适合对延迟敏感的任务。通过纯 RDMA 通信,DeepEP 能够最小化推理阶段的延迟,使得能够在论文中展示更高效的模型性能,增强论文的说服力。
使用 DeepEP 的具体方式安装与配置
DeepEP 的开源代码库已经发布在 GitHub 上,我们可以轻松地将其集成到自己的项目中。首先,通过以下命令克隆代码库:
git clone https://github.com/deepseek-ai/DeepEP.git然后,按照文档中的说明进行安装和配置。DeepEP 支持多种硬件环境,包括 NVLink 和 RDMA,用户可以根据自己的硬件条件进行相应的设置。
集成到 MoE 模型训练中
使用 MoE 模型的,DeepEP 可以直接替代传统的通信库,提供更高效的 All-to-All 通信支持。在模型训练脚本中,只需将 DeepEP 的通信模块导入,并替换原有的通信逻辑即可。例如:
from deepep import AllToAllCommunicatorcommunicator = AllToAllCommunicator()# 在训练循环中使用 DeepEP 进行数据分发和合并output = communicator.all_to_all(input_data)利用低精度计算优化资源
如果计算资源有限,可以启用 DeepEP 的 FP8 支持,以降低计算开销。在训练脚本中,只需将数据格式设置为 FP8,DeepEP 会自动处理低精度计算和数据分发:
from deepep import FP8Converterfp8_converter = FP8Converter()input_data_fp8 = fp8_converter.to_fp8(input_data)优化推理性能
对于需要展示模型推理性能的论文,可以使用 DeepEP 的低延迟推理解码内核。通过纯 RDMA 通信,DeepEP 能够显著减少推理延迟。在推理脚本中,启用低延迟模式:
from deepep import LowLatencyInferenceinference_engine = LowLatencyInference()result = inference_engine.run(input_data)自动调优与性能测试
DeepEP 提供了自动调优工具,能够在不同的硬件环境下获得最佳性能。用户可以通过运行测试脚本,找到最适合自己集群的配置:
python -m deepep.tune --config your_config.yaml结语DeepSeek 的开源周展示了其在 AI 基础设施领域的强大创新能力。从 FlashMLA 到 DeepEP,DeepSeek 不仅推动了技术的进步,还为学术界和工业界提供了宝贵的资源。
